Week in OSINT #2020–21
OPSEC, Offensive OSINT, open source and open formats! Combined with procedures, techniques and some forensics.
Hello all and welcome to yet another rather short newsletter. But then again, I think it's safe to assume that most of you don't like lengthy articles on a Monday morning 👀 This week I mostly have some articles that I found, but I also spent some time to include a useful tip, after reading a little blog post on PowerPoint a few days ago. And with that, let's dive into this weeks overview:
- OPSEC for Everyone
- Offensive OSINT
- Email to Flickr part 2
- Uncropping Media
- Office Open XML Format
Article: OPSEC for Everyone
This is part 3 already of a series of articles that were written by Twitter user 'cybersecstu'. I actually remember reading the first two articles last year, and I really would recommend them to anyone who is interested in operations security. This time he focusses on the process of classifying information about you, the possible impact it can have and how to handle.

Article: Offensive OSINT
Twitter user the_wojciech has written another huge article, this time about the world of the online porn industry. He dives into the company Mindgeek and starts to connect the dots, revealing how big this company actually is and what brands they operate. It's a large article with lots of information, but I think it's worth reading, especially since he is preparing a part 2. In that he will be explaining how to find domains and websites connected to a particular company.
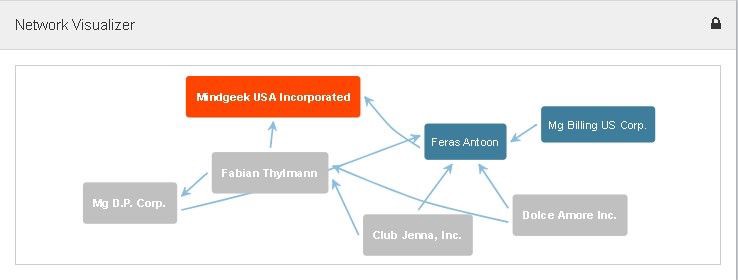
Link: https://www.offensiveosint.io/offensive-osint-s01e05-osint-corporate-espionage/
Tutorial: Email to Flickr part 2
In WiO 2020–18 I mentioned the article from Aware Online about how to retrieve Flickr user information by searching with an email address. In this second part he goes over the steps to create an actual script from scratch. Almost like a small introduction into Python for beginners. So if you want to learn a little bit more about this, then sit down and start coding!
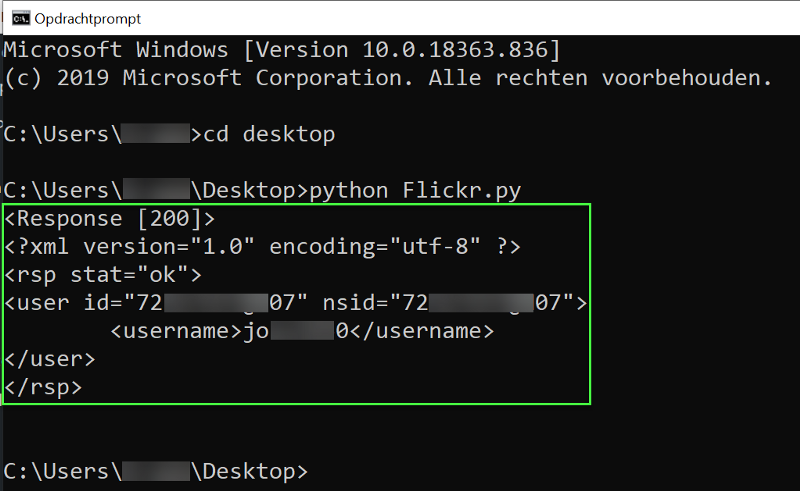
Link: https://www.aware-online.com/en/email-to-flickr-account-part2/
Tip #1: Uncropping Media
Twitter user AccessOSINT wrote a blog about how to investigate cropped images inside PowerPoint presentations. Because when you use the cropping tool, it doesn't really crop, it only changes the visible part of the image. Thus making it useful to dive into what might be in the document that isn't visible.
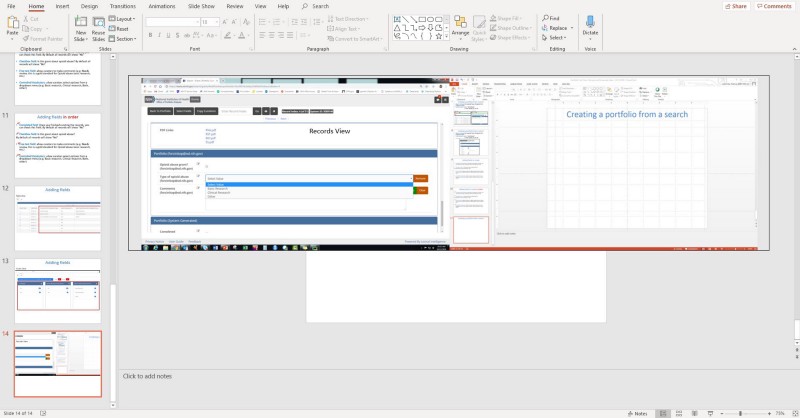
Link: https://medium.com/@osint/powerpoint-what-data-is-beneath-the-surface-2eb000ef95fb
Tip #2: Office Open XML Format
When I saw the tweet of AccessOSINT, I knew there was something that would even be better: Unpacking the files. The most used format nowadays for presentations, documents or sheets is the 'Open XML Format', or OOXML for short. The files can be recognised by the X at the end of the file extension, ie: pptx, docx and xlsx. Theses files are nothing more than zipped archives with an XML structure and a bunch of media files. You can extract all the contents and get your hands on the original sized images and maybe more.

Here is a little overview of what can be found inside an actual pptx file after extracting its contents:
- /docProps/core.xml
Document properties, with author names, dates et cetera - /media/
Folder with original images, sometimes with their original EXIF information intact! - /notesSlides/
All the notes that are in the presentation, one per slide. - /tags/
Folder with 'tagList' classes. It gives you information about the temp directory that was, thus giving hints on the OS it was made. - /slides/
All the individual slides, with even the possibility of finding actual folder structures of the maker inside:

There you have it, there is more than meets the eye and it is pretty much all a 'standard', so make sure you keep your eyes open. Unzip that docx, and dive into each and every file (or use some off the shelf, free forensic tools). A nice master thesis on forensics of the OOXML format can be found here:
Link: https://pdfs.semanticscholar.org/753b/09eeaecd588449493b0449a2bbfc895705b2.pdf
And for some extra housework, I can tell you that the OpenOffice format called 'OpenDocument', has a similar structure. It is also XML and full of little breadcrumbs like local file folders, original sized images with possibly EXIF data inside et cetera.

| Exeter Q-Step Resources
The University of Exeter has published a bunch of learning materials on GitHub. Topic include Python introduction and data analysis, introduction into OSINT, social network and data analysis in R, QGIS, SQL and a bunch of other interesting things. Thank you Adina Pintilie for sharing it!
Link: https://exeter-qstep-resources.github.io/
| Free Forensic
Learned some things about OOXML documents and what can be found inside? Want to learn a bit more about the field of digital forensics? Then this is the perfect resource for you! From basic security, to forensics and reverse engineering. Thanks MaikeMet1a for the tip!
Link: https://dfirdiva.com/training#FreeTraining
Have a good week and have a good search!